


Structured vs unstructured interviews: The full comparison
The STAR format: How to structure questions and evaluate answers
The STAR framework is the most widely used and research-backed structure for both asking behavioural interview questions and evaluating the answers you receive. Understanding it properly changes how you design your entire question set.
STAR stands for Situation, Task, Action, and Result. The framework works in two directions. It guides how you ask follow-up probes to obtain a complete answer, and it provides the structure against which you evaluate the completeness and quality of what a candidate tells you.
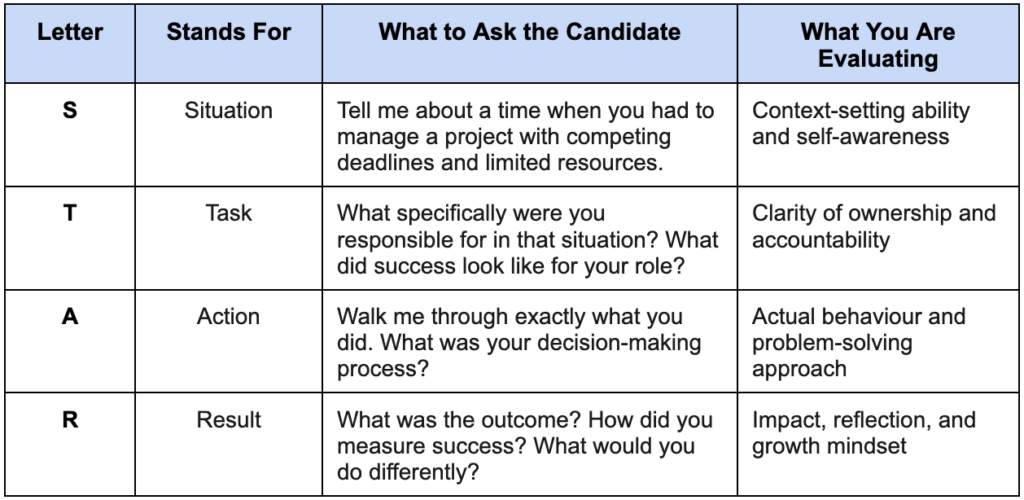
The most common mistake interviewers make with STAR is accepting a partial answer and scoring it as complete. A candidate who describes the situation and the result without ever clearly explaining the specific actions they personally took has given you half an answer. You have learned what happened to them. You have not learned what they did.
This is where structured probing matters enormously. When a candidate skips straight to the result without explaining their decision-making, the interviewer needs to bring them back. What specifically did you do? What options did you consider before choosing that approach? What was your personal contribution, as distinct from what the team did?
These probes are not peripheral. They are the moments when you get the real answer. And they require an interviewer who is trained to notice when a STAR response is incomplete and skilled enough to redirect without making the candidate feel interrogated.
A complete STAR answer is evidence. An incomplete STAR answer is a story. Your job as an interviewer is to know the difference and keep probing until you have evidence.
How does AI dynamically adapt follow-up questions in real time?
This is where the conversation moves from structured interviewing principles to what AI actually enables, which human interviewers cannot reliably deliver at scale.
When easemyhiring.ai conducts a first-round interview, it does not simply read a list of pre-set questions and move on regardless of how the candidate responds. It analyses the candidate’s response in real time and adapts its follow-up questions based on what it hears. This is dynamic probing, and it is the capability that most closely mirrors what a skilled human interviewer does in their best moments, applied consistently to every candidate every time.
The system is built to detect specific response patterns that signal an incomplete or insufficiently evidenced answer and trigger targeted follow-up questions designed to surface what is actually there underneath the surface response.

What makes this capability significant is not just the sophistication of the follow-up questions themselves. It is the consistency with which they are applied. A human interviewer might notice that a candidate’s answer was vague and probe effectively with candidate one and candidate twenty. By candidate 40, after a full day of interviews, the same signal might slip past unnoticed. The follow-up is not being requested. The weak answer is scored as adequate. A candidate who should have been eliminated advanced.
Easemyhiring.ai applies the same probing framework to candidate one and candidate four hundred. The quality of evaluation does not degrade with volume. The follow-up questions that reveal genuine competency are always asked, and the performance report reflects the full depth of what each candidate actually demonstrated, not what an interviewer remembered at the end of a long day.
Dynamic AI follow-up questioning does not replace the skilled human interviewer. It ensures that the skill level of the best interview you have ever run is the baseline for every single interview you conduct.
